Setting up an AWS Multi-Account Strategy for Fun nor Profit
Daan Debie / February 09, 2022
9 min read
AWS Multi-Account Strategy
Don’t you just love the freedom of working at an early stage startup, with a relentless focus on product and a blatant disregard for any non-functional distractions? I do.
When I started working at Source about 9 months ago, it was just me — the first employee — and the 2 founders. The only code written, were a couple of demos for investor pitches which we threw away quickly. I was in the luxurious position to be able to start building our product from scratch. I deployed everything I built into a single AWS root account.
Fast-forward to today, and we’re with more than 30 people — most of whom are software engineers and data scientists writing and deploying code. In December, we finished migrating all of our infrastructure to a multi-account setup in AWS. In this blog post I want to explain why we did this and what our multi-account setup looks like.

When the Cracks Start Showing
As mentioned, when we started everything was deployed into a single AWS account. When the moment came that we wanted to have separate development and production environments, I created 2 VPCs in the same account and deployed an identical setup in both, each consisting of:
- An ECS cluster for our backend services
- A PostgreSQL database on RDS for persistence
- Some S3 buckets for storing unstructured data
- Some Lambdas for data processing.
It looked something like this:
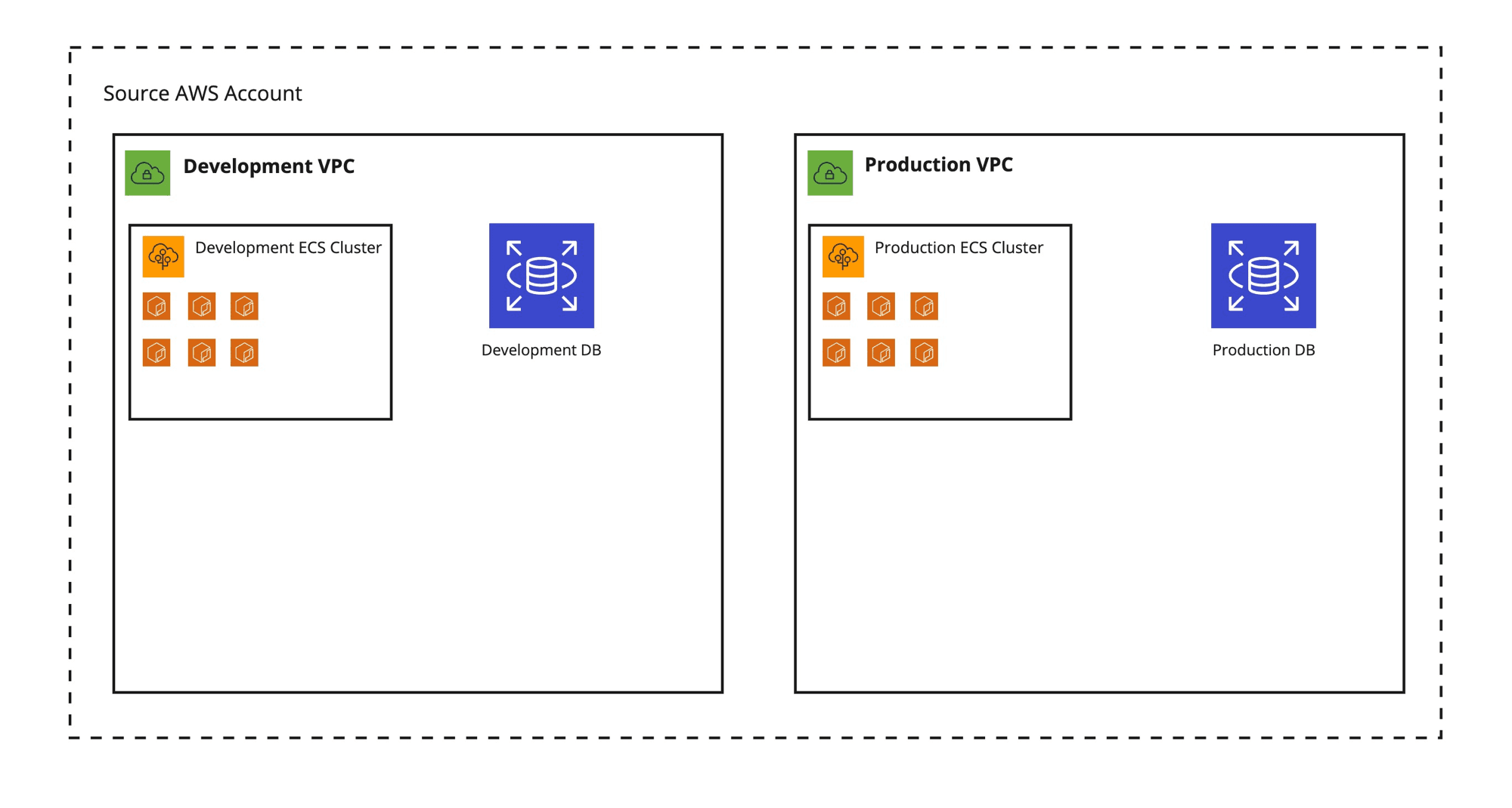
I deployed our applications and services (except for our frontend, which is deployed on Vercel) in two identical VPCs — still living in the same AWS account — and called it a day.
When we started building our team and the first software engineers and data scientists joined, I created IAM users for everyone and solved access control by defining groups with specific IAM policies (permissions) attached to them and adding the IAM users to those groups. The more people joined the team, the more diverse the access requirements became, for example:
- A data scientist does not need access to the same things as a software engineer
- A junior person does not need the same level of access as a senior person
And there are many more subtle differences in the kind of access to infrastructure people need and should have.
Single-Account Problems in a Nutshell
In the end, our single-account setup made it difficult to build a secure and resilient infrastructure:
- It is less secure. If someone gains access to this one account, they have access to everything. It’s hard to separate resources for different environments (e.g. production, development) and treat these resources differently security wise.
- It is less safe and resilient. If something goes wrong with one environment (e.g. development), it’s easy to affect services in other environments (e.g. production) when they’re in the same account. They get caught in the blast radius
- It’s hard to maintain. All AWS resources live in 1 account so when different users need different levels of access, this needs to be controlled on a per-resource level, which is hard to configure and keep track of
- It’s hard to control spend in this way. Once certain access is granted to create new resources, there is no limit to how many resources can be created and what services can be used
Many of these problems can actually be solved — even in a single-account setup — by "properly" tagging all your AWS resources and creating elaborate IAM policies for users and resources based on those tags. But such a tagging strategy will quickly become really complex and will cost a lot of time to maintain. Needless to say that it’s quite error-prone as well.
Aside from the security and safety implications, our setup had some other problems:
- All IAM Users were created and managed through CDK/CloudFormation, because we love Infrastructure
as Code. This is problematic:
- It makes it possible for anyone with access to CloudFormation to see all Access Keys + Secrets
- It’s not easy to scale, because we now need to manually deploy a CDK stack when new users need to be added
- It’s hard to broadly define policies for different access patterns in this way
- Users have to use a separate set of credentials for accessing AWS instead of using an existing login (i.e. their Google Workspace account)
There Is a Better Way
When I was researching a way forward, I found many blog posts extolling the virtues of putting your infrastructure into multiple AWS accounts. But before getting a better understanding of how this would work, I had some reservations about using multiple AWS accounts:
- Do I need to create multiple IAM users for each person, so they can log in to multiple accounts?
- How do we control costs? Do I need to keep track of different bills for each account?
- How can I share resources, such as reusable Docker images or shared data in an S3 bucket?
AWS offers a nice solution to these problems (and others) in the form of AWS Organizations
According to AWS:
An organization is an entity that you create to consolidate a collection of accounts so that you can administer them as a single unit.

AWS Organizations lets you organize a bunch of related AWS accounts in a hierarchical, tree-like structure. It will let you manage all those accounts from one central management account. With Consolidated Billing, all bills from all member accounts will be aggregated to the management account where you can pay them as one.
Arguably the most powerful feature of AWS Organizations is that you can group the member accounts together in Organizational Units (OUs) and apply common security policies to those. This lets you define permissions and control access in broad strokes — and from a central place — while keeping the natural separation of concerns that comes from using separate AWS accounts to organize your infrastructure.
Easy User Management Using AWS SSO
When it comes to user management, AWS Organizations offers the convenience of letting users log in with one user account (not to be confused with AWS account), using AWS Single Sign-on. AWS SSO lets you create users in the root account (also known as management account) of your organization and give them login credentials within AWS itself or link them to an external identity provider like Google or Active Directory. You can then give these users access to specific AWS accounts within your AWS Organization. Users can be assigned specific permissions within these accounts. (I will explain more on how this works in a later blog post)
This has several advantages compared to using regular IAM users:
- Users only need one set of credentials to log into multiple AWS Accounts
- Everyone can log in using credentials they already use on a daily basis (Google Workspace credentials in our case)
- There is no more need to create and manage IAM users through CDK
- There is no credential leakage through CloudFormation
- We can potentially automate user creation by programmatically syncing AWS users and Google Workspace users
What Does a Good AWS Organization Setup Look like?
Well, I don’t know. But I do know what works for us so far
When deciding what AWS accounts to create and how to group them, I had the following requirements:
- There must be a clear separation between Development, Staging and Production resources/infrastructure
- It should be easy to control access to resources with different security and "stability" properties without having to manually define lots of policies
- We want to give sandbox accounts to individual engineers and data scientists to allow and encourage experimentation while limiting spend
- Sensitive resources and data should be placed out of reach from easy access when not needed for normal day-to-day activities
- We want to follow the Principle of least privilege: give only the minimum set of permissions to allow access to exactly the resources a person or service needs to perform their job and not more.
- We want as little overhead and bureaucracy as possible within the constraints of the previous requirements
This was aside from solving the aforementioned problems we had with our single-account setup.
This led me to create the following accounts, organized by Organizational Unit:
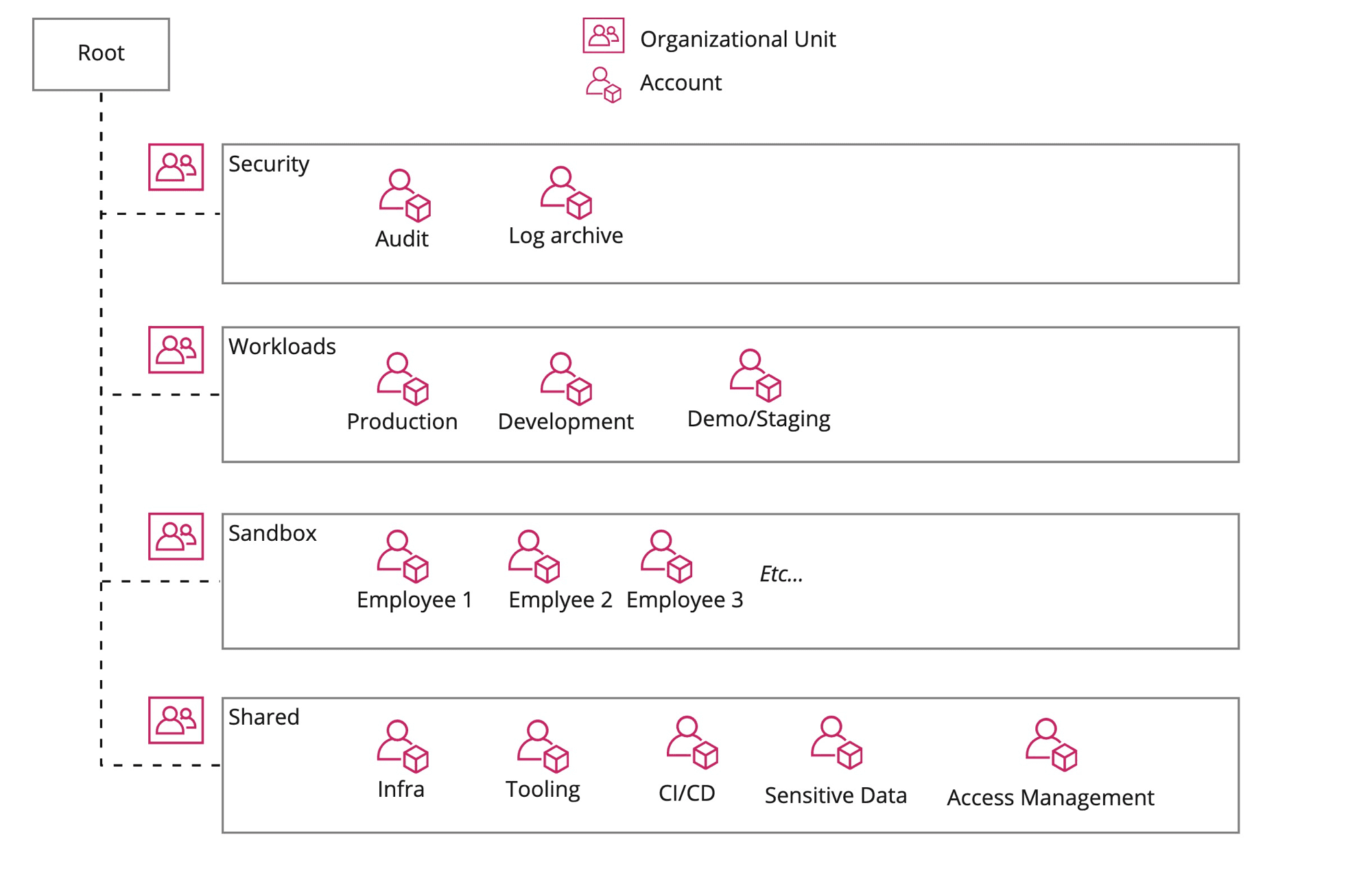
Some notes and highlights:
- Workloads: this contains the "meat" of the infrastructure used for the day-to-day running of
our products. Each of the workload accounts represents a different environment, like Production,
Staging and Development. They all have a similar setup and contain basic infrastructure like:
- a VPC network with private and public subnets
- a couple of ECS clusters for running services in (Docker) containers
- some PostgreSQL databases on RDS
- many lambdas for data processing, machine learning etc.
- Shared: as the name implies, this OU houses accounts with infrastructure that is shared
between workloads/services on other accounts. Some highlights:
- Access Management: this contains IAM users for external machines and services that need to access AWS infrastructure on our behalf. Given the sensitive and "dangerous" access some of these machine users get, the Access Management account is tightly locked down. Example of an IAM user in this account, is the Github Actions user that is used to deploy code to our workload accounts. This user assumes roles within the workload accounts for deployments.
- Sensitive Data: this account holds sensitive data that is not needed for day-to-day operations, but is occasionally used for training ML models and building new features
- Infra: contains shared infrastructure, such as our central Docker registry. Docker images pushed to this registry are automatically replicated to our workload accounts for easy access
- Sandbox: our employees occasionally need to experiment with AWS services so they get a sandbox account to do so, without messing up our operational workloads. Budget restrictions are placed on these accounts
Conclusion
Using AWS Organizations we have now set up our infrastructure at Source in such a way that it is more secure and also more scalable and easier to maintain from a security perspective. Our Software Engineers and Data Scientists have easier access to the infrastructure, services and resources they need — using only one set of credentials — without exposing them to sensitive data and/or critical infrastructure.
In future blog posts I will elaborate on the steps taken to set all of this up and share some practical guides on how to use a multi-account setup on a day-to-day basis.
Thanks to Dan for proofreading this ❤️